A Comparative Study on Dynamic Graph Embedding based on Mamba and Transformers
Overview
Dynamic graph embedding has emerged as an important technique for modeling complex time-evolving networks across diverse domains. While transformer-based models have shown promise in capturing long-range dependencies in temporal graph data, they face scalability challenges due to quadratic computational complexity. This study presents a comparative analysis of dynamic graph embedding approaches using transformers and the recently proposed Mamba architecture, a state-space model with linear complexity. We introduce three novel models: TransformerG2G augment with graph convolutional networks, DG-Mamba, and GDG-Mamba with graph isomorphism network edge convolutions. Our experiments on multiple benchmark datasets demonstrate that Mamba-based models achieve comparable or superior performance to transformer-based approaches in link prediction tasks while offering significant computational efficiency gains on longer sequences. Notably, DG-Mamba variants consistently outperform transformer-based models on datasets with high temporal variability, such as UCI, Bitcoin, and Reality Mining, while maintaining competitive performance on more stable graphs like SBM. We provide insights into the learned temporal dependencies through analysis of attention weights and state matrices, revealing the models’ ability to capture complex temporal patterns. By effectively combining state-space models with graph neural networks, our work addresses key limitations of previous approaches and contributes to the growing body of research on efficient temporal graph representation learning. These findings offer promising directions for scaling dynamic graph embedding to larger, more complex real-world networks, potentially enabling new applications in areas such as social network analysis, financial modeling, and biological system dynamics.
Keywords: graph embedding, transformers, dynamic graphs, link prediction, state-space models, long-term dependencies
Paper link | GitHub link| Citation
Methodology
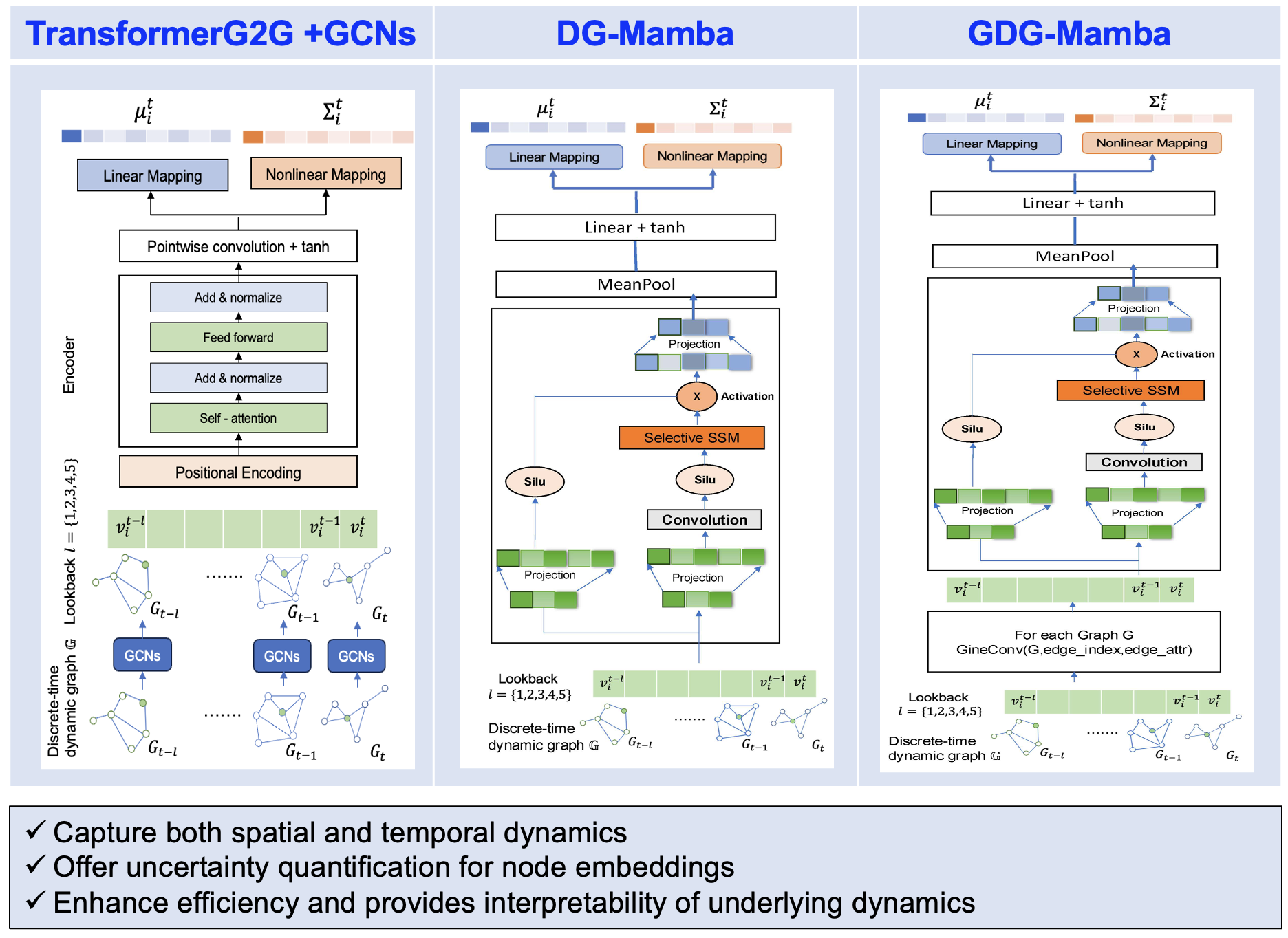
ST-TransformerG2G Model
The proposed ST-TransformerG2G model enhances the previous TransformerG2G model with Graph Convolutional Networks (GCNs). Key features include:
- An additional GCN block with three GCN layers to capture spatial interactions for each graph snapshot.
- Node embeddings generated by the GCN block are fed into a vanilla transformer encoder module.
- Positional encoding is added to each input node token embedding.
- The final output representation of each node is a multivariate normal distribution.
DG-Mamba Model
The main architecture of the proposed DG-Mamba model processes a sequence of discrete-time graph snapshots {G_t}_{t=1}^{T}. Key features include:
- A look-back parameter l = {1,2,3,4,5} for historical context integration.
- Each graph snapshot undergoes projection and convolution to capture localized node features while maintaining spatial relationships.
- A State-Space Model (SSM) layer efficiently captures long-range temporal dependencies using the selective scan mechanism (Mamba architecture).
- The output of the Mamba layer is passed through an activation function for non-linearity, followed by mean pooling to generate an aggregate representation.
- A linear projection layer with tanh activation refines the node embeddings.
- Two additional projection heads (one linear projection layer and one nonlinear projection mapping with ELU activation function) are used to obtain the mean and variance of Gaussian embeddings.
GDG-Mamba Model
The main architecture of the GDG-Mamba model processes a series of discrete-time graph snapshots {G_t}_{t=1}^{T} using GINE convolution. Key features include:
- Enhanced spatial representation of the graph by considering both node and edge-level features at each timestamp.
- Generated graph sequence representations are processed through the Mamba block to capture temporal dynamics.
- Mean pooling and a linear layer with tanh nonlinearity are applied before outputting the final Gaussian embeddings.
- The model incorporates node and edge-level features across both spatial and temporal dimensions.
Results
We used five different graph benchmarks to validate and compare our proposed models. A summary of the dataset statistics - including the number of nodes, number of edges, number of timesteps, and the distribution of train/validation/test splits with specific numbers of timesteps, as well as the embedding size - is provided in Table 1.
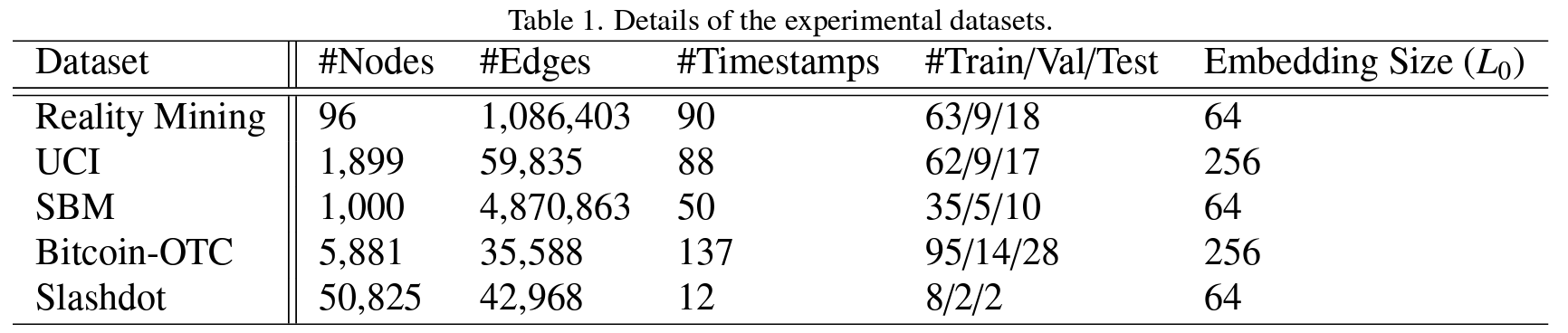
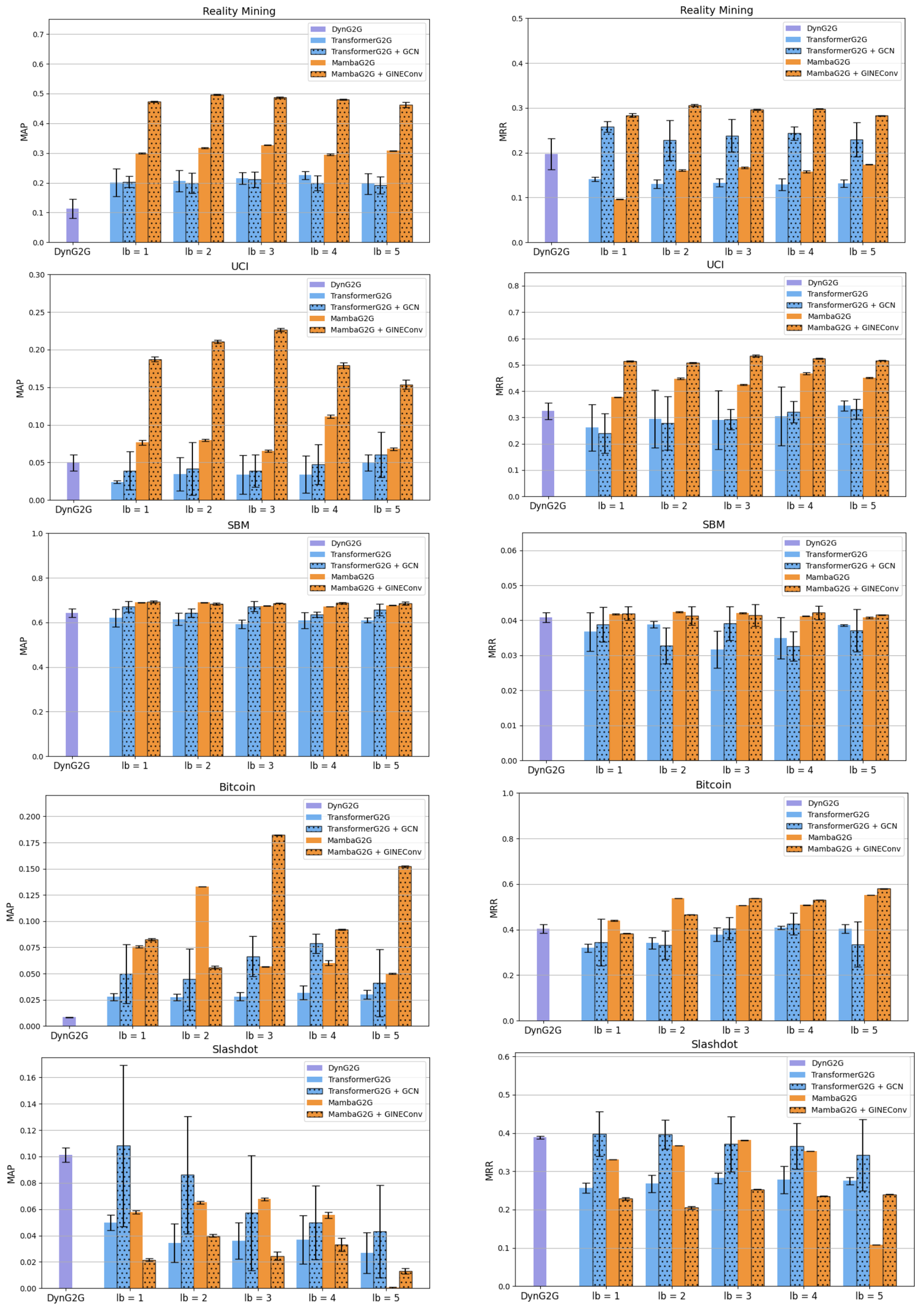 Figure 4. Comparison of MAP and MRR for temporal link prediction task for DynG2G, TransformerG2G, ST-TransformerG2G (i.e., TransformerG2G + GCN), DG-Mamba, GDG-Mamba (i.e., DG-Mamba + GINEConv) models.
Figure 4. Comparison of MAP and MRR for temporal link prediction task for DynG2G, TransformerG2G, ST-TransformerG2G (i.e., TransformerG2G + GCN), DG-Mamba, GDG-Mamba (i.e., DG-Mamba + GINEConv) models.
Aknowlegement
We would like to acknowledge support from the DOE SEA-CROGS project (DE-SC0023191) and the AFOSR project (FA9550-24-1-0231).
Citation
@article{parmanand2024comparative,
title={A Comparative Study on Dynamic Graph Embedding based on Mamba and Transformers},
author={Parmanand Pandey, Ashish and Varghese, Alan John and Patil, Sarang and Xu, Mengjia},
journal={arXiv e-prints},
pages={arXiv--2412},
year={2024}
}